
The shift to AI-first search means crawlers are smarter, processing content not just for keywords but for context, intent, and relationships. For small to mid-sized businesses, this presents both a challenge and an opportunity. This article cuts through the noise to provide a pragmatic roadmap for optimizing your site architecture, ensuring your valuable content is efficiently discovered, understood, and ranked by intelligent search systems, even with limited resources.
You’ll gain clear judgment calls on which technical SEO elements truly matter for AI-driven indexing today, helping you prioritize efforts that yield real results and avoid time sinks that offer little return.
Understanding AI-First Crawlers and Indexing
Intelligent crawlers, powered by advanced AI models, move beyond simple keyword matching. They analyze the semantic meaning of your content, understand the relationships between topics, and interpret user intent with greater sophistication. This means your site’s architecture isn’t just about guiding a bot; it’s about presenting a clear, logical map of your expertise and value that an AI can fully comprehend.
For SMBs, this translates to ensuring your site’s structure clearly communicates hierarchy, relevance, and authority. A well-organized site helps AI connect the dots, making your content more discoverable and understandable in complex search queries.
Prioritizing Core Site Architecture Elements
Effective site architecture for AI-first search focuses on clarity and efficiency. Here are the elements that demand your immediate attention:
- Internal Linking Structure: This remains paramount. A robust internal linking strategy guides both users and AI crawlers through your site, establishing topic authority and distributing link equity. Think of it as creating a web of related knowledge. Strong internal links help AI understand the depth and breadth of your content on a given subject.

Internal linking structure example - Canonicalization: With AI’s ability to understand semantic similarity, duplicate content issues can be more subtle. Proper canonical tags are critical to tell search engines which version of a page is the definitive one, preventing dilution of authority and ensuring AI focuses on your preferred content.
- XML Sitemaps: While AI crawlers are adept at discovery through internal links, XML sitemaps still serve as a valuable blueprint. They provide a comprehensive list of your important pages, aiding in initial discovery and ensuring no critical content is missed, especially for newer sites or those with complex structures.
- Robots.txt: This file is your first line of defense, directing crawlers away from low-value or sensitive content. Efficient use of robots.txt ensures your crawl budget is spent on pages that truly matter for your business goals.

What often gets overlooked in the pursuit of a clean site architecture is the ongoing maintenance burden. Internal linking, for instance, isn’t a one-time setup. As content grows and evolves, the “web of related knowledge” can quickly become tangled or sparse. Teams, under pressure to publish new material, frequently deprioritize auditing and updating existing internal links. This leads to a gradual accumulation of orphaned pages or diluted link equity, silently eroding the authority of valuable content over time. The initial effort put into a robust structure can decay, making it harder for AI to fully grasp your site’s topical depth.
Similarly, canonicalization, while conceptually straightforward, often presents practical challenges that lead to non-obvious failure modes. Complex sites with faceted navigation, dynamic URLs, or international versions can generate thousands of technically distinct but semantically similar pages. Implementing canonical tags correctly across these variations requires a deep understanding of both technical SEO and user intent. A common pitfall is applying blanket canonical rules that inadvertently hide valuable content or point to non-indexable pages, effectively telling search engines to ignore your preferred version. This isn’t just a technical error; it’s a strategic misstep that can silently suppress your best content from search visibility.
Finally, while robots.txt is crucial for managing crawl budget, there’s a fine line between efficient blocking and accidental self-sabotage. The temptation to aggressively disallow directories to “save budget” can backfire. A common oversight is blocking access to CSS, JavaScript, or image files that are critical for rendering the page. Modern AI crawlers need to render pages fully to understand their layout, user experience, and overall content quality. Preventing this rendering can lead to a degraded understanding of your content, even if the HTML itself is accessible. The immediate perceived benefit of “saving crawl budget” is often outweighed by the downstream effect of AI misinterpreting or devaluing your pages.
Content Semantics and Structure for AI
How you structure your content on the page is just as important as how your pages link together. AI thrives on well-organized, semantically rich content.
- Semantic HTML: Use HTML5 elements like
<article>,<section>,<nav>, and proper heading tags (<h1>through<h6>) to define the structure and meaning of your content. This helps AI parse and understand the different components of your page, distinguishing main content from sidebars or navigation. - Structured Data (Schema.org): This is not just a recommendation; it’s a necessity for AI-first search. Structured data provides explicit clues to search engines about the entities, relationships, and context within your content. Prioritize high-impact types like
Product,Article,FAQPage, andLocalBusiness. This direct communication helps AI interpret your content accurately, leading to richer search results and better visibility.
Structured data implementation workflow - Content Hubs and Topic Clusters: Organize your content around core topics, with a central “pillar page” linking out to supporting cluster content. This demonstrates comprehensive authority on a subject and provides a clear, logical path for AI to understand your expertise. content hubs topic clusters

While the concept of semantic HTML is straightforward, its consistent application across a growing site is where many teams stumble. It’s easy to overlook the cumulative effect of inconsistent tagging, especially when different authors or developers contribute over time. A page might start with perfect <article> and <section> usage, but subsequent updates or new content might revert to generic <div>s, creating a patchwork. This inconsistency can be just as confusing for AI as no semantics at all, leading to a less reliable understanding of your content’s true hierarchy and meaning. The hidden cost here isn’t just the initial effort, but the ongoing vigilance required to maintain structural integrity.
Similarly, structured data isn’t a one-time implementation. A common failure mode is treating it as a “set it and forget it” task. Content changes, product updates, or even minor tweaks to an FAQ page can render existing schema invalid or outdated. Forgetting to audit and update structured data means you could be sending conflicting or incorrect signals to AI, which can negate the benefits or even lead to penalties. The pressure to launch often means the crucial step of ongoing validation and maintenance planning for structured data gets deprioritized, creating technical debt that’s harder to fix later.
The theoretical elegance of content hubs and topic clusters often clashes with the practical realities of limited resources. While the ideal is a fully fleshed-out, interconnected web of content demonstrating comprehensive authority, attempting to build this perfectly from scratch can lead to analysis paralysis and delayed publishing. For small teams, the trap is spending too much time architecting the “perfect” hub instead of producing valuable content. It’s better to start with a strong pillar page and a few core supporting articles, then incrementally build out the cluster over time. Don’t let the pursuit of an ideal, exhaustive structure prevent you from getting valuable, semantically rich content live. Prioritize publishing and iterating over achieving theoretical perfection.
What to Deprioritize or Delay Today
For SMBs with limited resources, making smart trade-offs is essential. Here’s what you can often delay or skip for now:
Avoid chasing every speculative “AI ranking factor” or over-optimizing for niche, unproven AI features. Many consultants push complex, resource-intensive strategies that offer marginal gains for small teams. Instead, focus on the foundational elements that consistently improve content understanding for any intelligent system. For example, while advanced JavaScript rendering solutions can be beneficial, a complete re-architecture of a functional site solely for this purpose might be a significant undertaking that can be delayed if your core content is already accessible to crawlers. Similarly, obsessive, minute-by-minute crawl budget analysis for smaller sites (under a few thousand pages) often yields less return than simply fixing broken links and ensuring all important pages are internally linked.
Actionable Steps for SMBs
Start with a practical, phased approach:
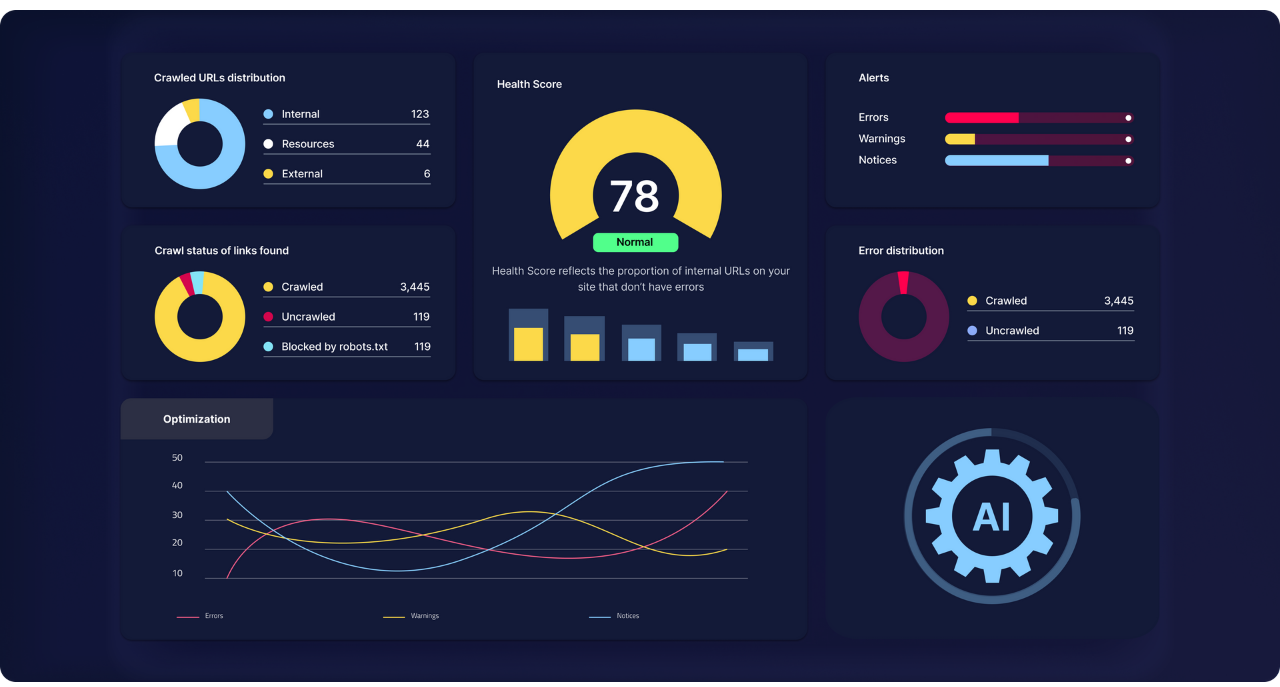
- Conduct a Site Architecture Audit: Use tools like Google Search Console google search console crawl stats and ahrefs.com or semrush.com to identify orphan pages, broken links, redirect chains, and pages with thin content. Prioritize fixing these fundamental issues first.

Google Search Console crawl stats - Map Your Content: Understand how your content relates to user journeys and business goals. Ensure your internal linking reflects this logical flow, guiding users and AI through your most valuable assets.
- Implement Foundational Structured Data: Focus on the schema types most relevant to your business (e.g., Product, Article, LocalBusiness, FAQPage). Don’t try to implement every possible schema type at once.
- Strengthen Internal Linking: Actively review and improve internal links, ensuring related content is well-connected and important pages receive adequate internal link equity.
- Monitor and Iterate: Regularly check your crawl stats and index coverage reports in Google Search Console. This feedback loop is crucial for identifying new issues and validating your architectural improvements.

Leave a Comment